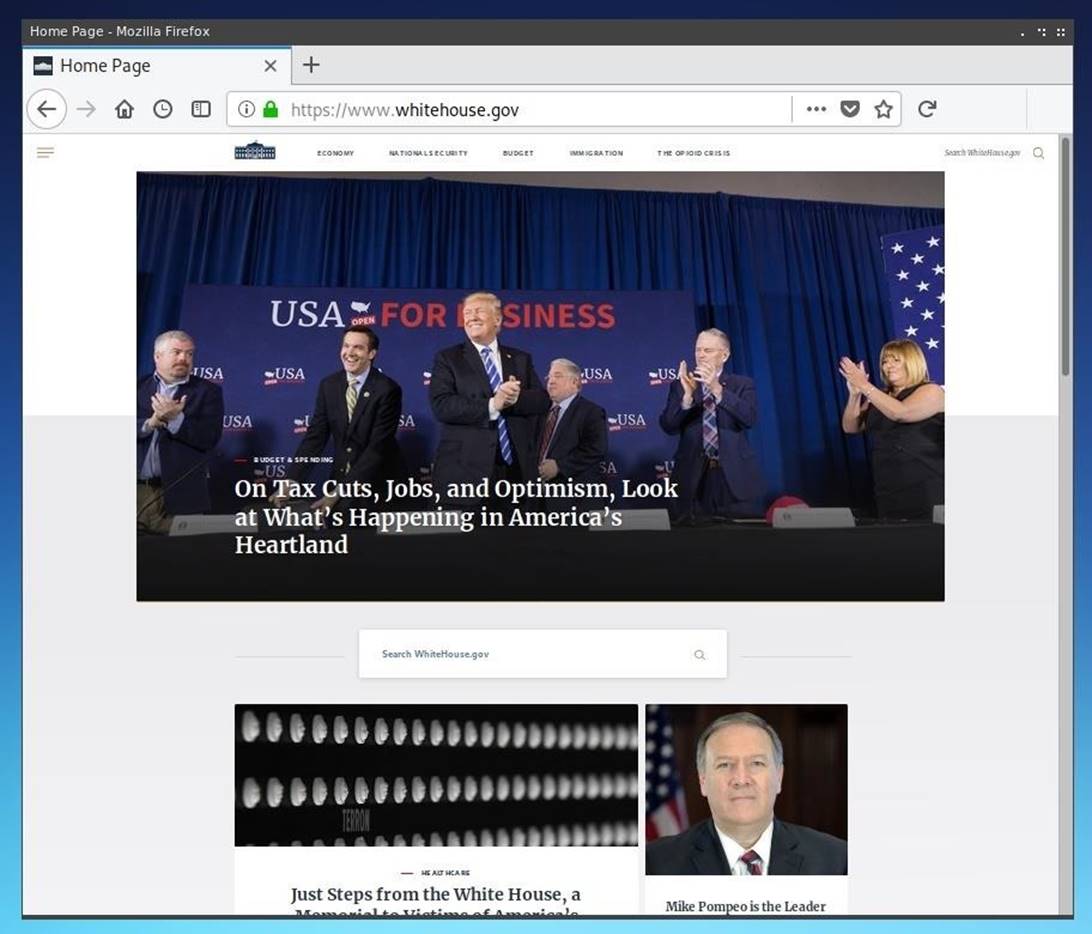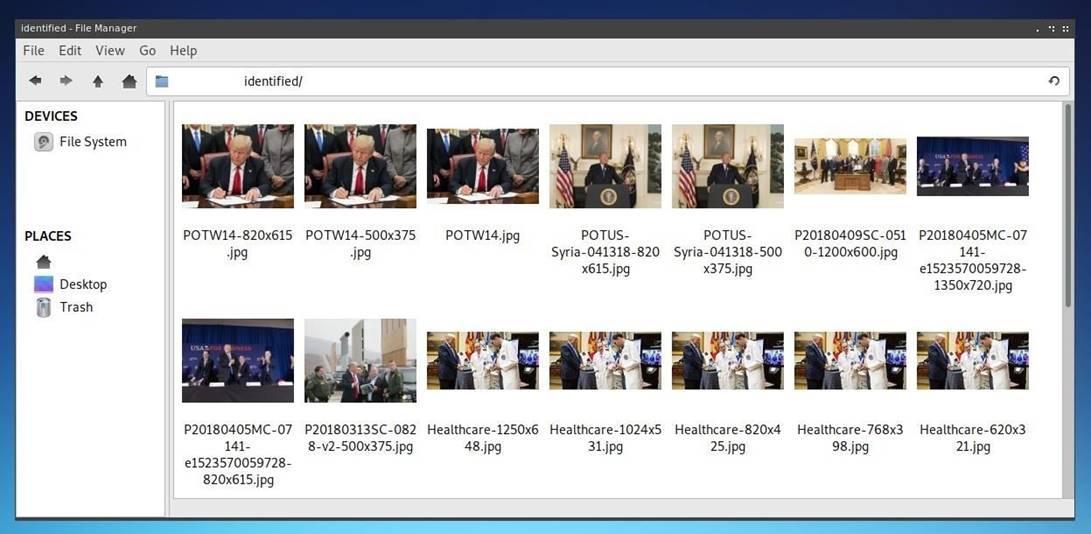






















Анализ фотографий и социальных связей может стать огромным подспорьем при социальной инженерии.
Анализ фотографий и социальных связей может стать огромным подспорьем при социальной инженерии. Если мы знаем, кем является персона и круг знакомых этой персоны, то вполне можем выявить связи внутри компании, что впоследствии позволит реализовать изощренные целевые атаки с использованием социальной инженерии.
Термин OSINTили по другому разведка на основе открытых источников охватывает такие сферы, как анализ, оценку и применение публично доступной информации. Приведу цитату ЦРУ: «Чтобы получить нечто ценное, не обязательно пытаться достать исключительно конфиденциальную информацию. Понимание окружающей реальности приходит через чтение блогов и специальных журналов, просмотр телевизора и изучение других общедоступных источников».
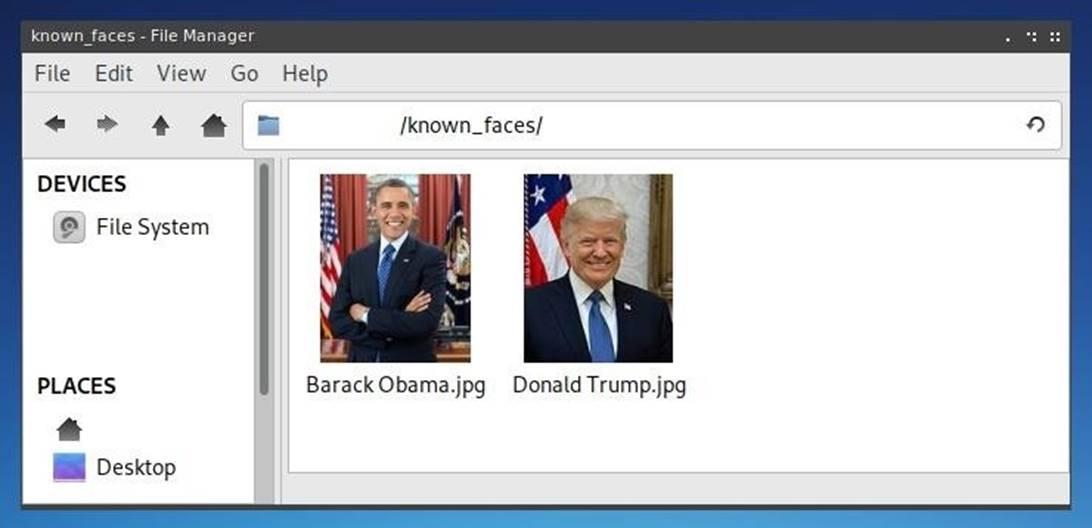
Помимо текста общедоступная информация хранится в интернете в виде фотографий, которые, в основном, фильтруются и обрабатываются людьми вручную при помощи графического редактора с целью последующего анализа полученных результатов. Однако с появлением программного обеспечения, заточенного под распознавание лиц, многие операции стало возможным автоматизировать.
По поводу технологии распознавания лиц уже появилось много статей и дискуссий, например, касательно биометрии или того, как эта технология влияет на информационные массивы и частную жизнь. Несмотря на то, что распознавание лиц в основном используется на таких платформах какFacebook или правоохранительными органами по всему миру, любой желающий может воспользоваться схожими бесплатными приложениями с открытым исходным для решения своих собственных задач.
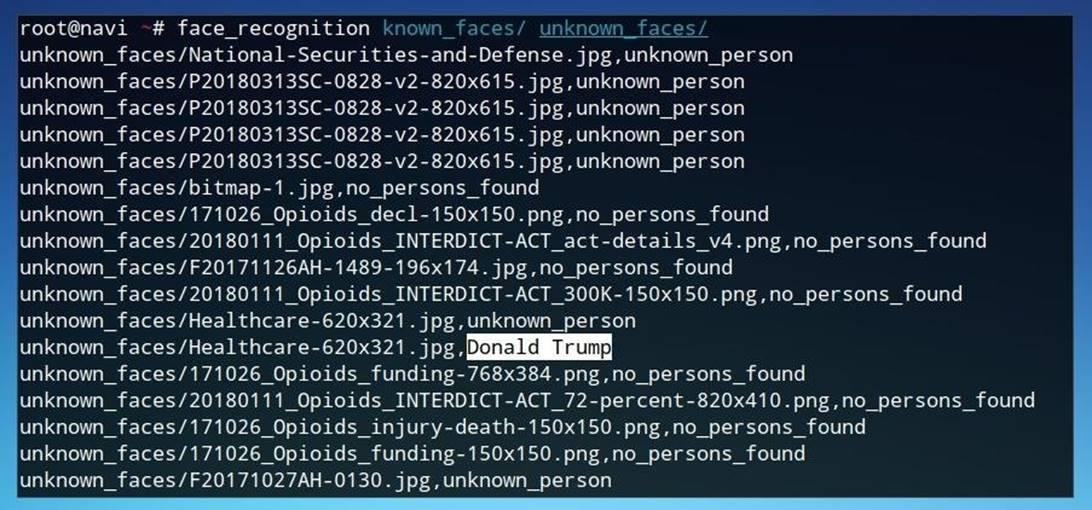
В этой статье мы рассмотрим, как использовать библиотеку Face Recognitionна базеPython для поиска и анализа изображений. Кроме того, мы рассмотрим пакетную обработку фотографий и методы получения статистики с целью того, чтобы впоследствии сделать выводы об отдельной персоне или целом вебсайте.
Шаг 1: Установка зависимостей
Библиотека Face Recognition, которую мы будем использовать, доступна напрямую в менеджере пакетовPip вLinux иmacOS. Несмотря на то, что этот пакет вWindowsофициально не поддерживается, доступно руководство по установкеи сконфигурированный образ виртуальной машины.
Перед началом установки проверьте, присутствуют ли последние обновления в вашей операционной системе. В дистрибутивах на базеDebian(например,Ubuntu иKali) обновление и установка нового программного обеспечения делается при помощи следующей команды:
sudo apt-get update && apt-get upgrade
В некоторых дистрибутивахPip доступен по умолчанию. В противном случае последнюю версию этого менеджера можно установить при помощи следующей команды:
sudo apt-get install python-pip
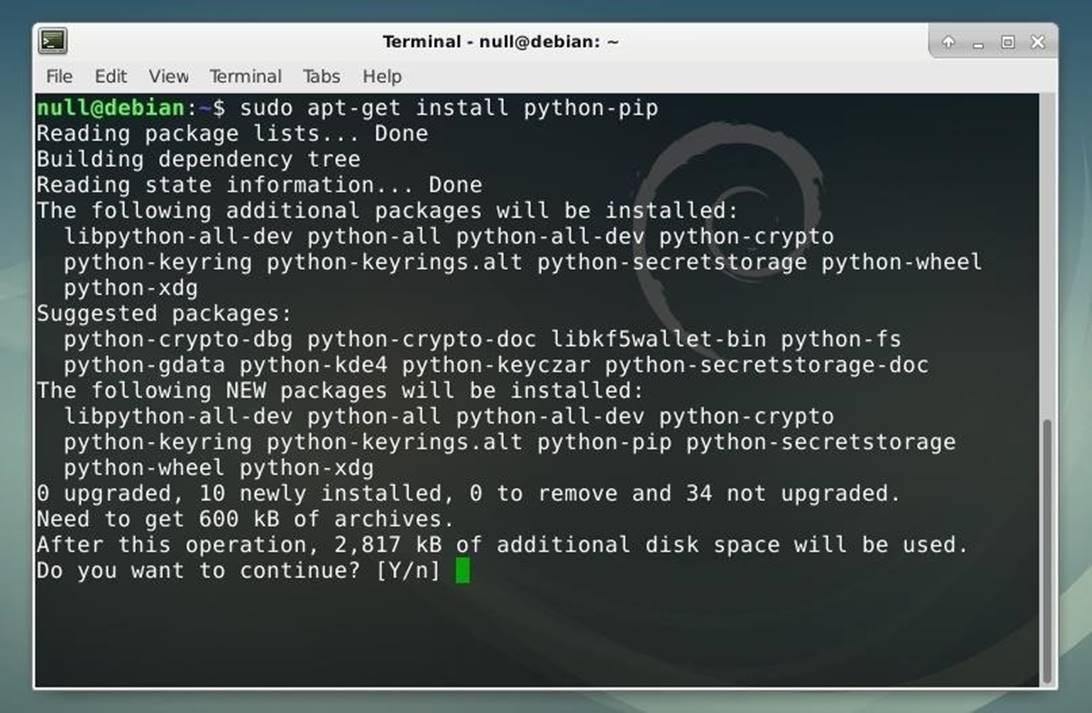
Рисунок 1: Установка менеджера пакетовPip
Далее устанавливаем библиотекуFace Recognition при помощи следующей команды:
sudo pip install face_recognition
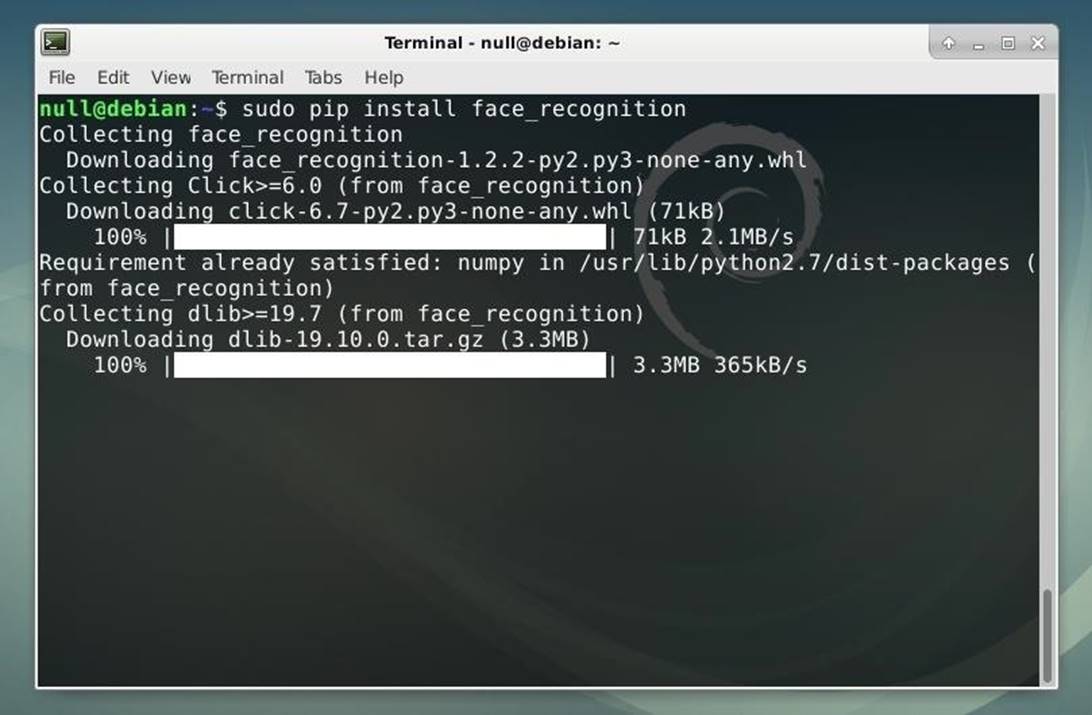
Рисунок 2: Установка библиотекиFace Recognition
Теперь библиотека готова к использованию.